Page 1 of 1
Despeckle PDF before OCR
Posted: Tue May 13, 2014 10:58 am
by David.P
Hi forum,
not exactly sure if I'm in the correct sub-forum, but I've got an urgent problem regarding OCR.
I have some large pdf files here that have been generated elsewhere by scanning paper documents (or something). Unfortunately, some mad conversion setting has been used such that the text looks like this:
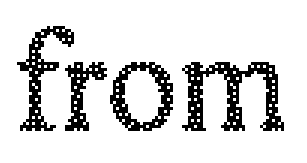
With all of the OCR tools that I own, such text is not recognisable.
However, after running a Median Filter (aka "despeckle") over the image (using IrfanView), the image looks like this:
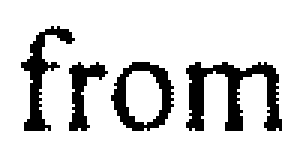
... and is perfectly converted to text for example by Ad*be Acr*bat ClearScan:

Now the problem is, how can I batch-despeckle those PDF documents of several hundred pages size, such that I can OCR them afterwards with the tool of my choice?
IrfanView & Ghostscript basically are a terrible team for handling PDF. Batch conversion seems to be almost impossible there (or takes like days to complete, if at all).
Thanks HEAPS already for any help,
Regards David.P
Re: Urgent -- despeckle PDF without/before OCR
Posted: Tue May 13, 2014 1:08 pm
by Tracker Supp-Stefan
Hello David,
If those files contain one image per page you can try to use the PDF Tools to export all pages from the PDF file(s), then batch despeckle them, and then make new PDF files and OCR them at the same time using the Editor's File -> New Document -> From Images... option.
Regards,
Stefan
Re: Urgent -- despeckle PDF without/before OCR
Posted: Tue May 13, 2014 2:07 pm
by David.P
Yep Stefan, thanks -- that's the way I could do it with IrfanView as well (IrfanView is great for images, but terrible with PDF).
However, I would rather (if that is possible at all) despeckle the PDF files directly because of their size (like hundreds of pages) instead of having to disassemble and reassemble them.
Actually, Adobe Acrobat can do it (despeckle PDF files) -- sort of, because the effect is much to weak in the present case.
If there is no other way, I shall disassemble those files...

Best regards
David
Re: Urgent -- despeckle PDF without/before OCR
Posted: Tue May 13, 2014 3:13 pm
by Tracker Supp-Stefan
Hi David,
There's no way (yet) for you to directly manipulate the images inside the existing files, however - have you tried to maybe "reprint" them through our printing drivers with some graphics compression options? This might give you the desired despeckled images?
Regards,
Stefan
Re: Urgent -- despeckle PDF without/before OCR
Posted: Tue May 13, 2014 3:16 pm
by David.P
Thank you Stefan, that could be indeed another possible option, depending that some kind of blurring can be achieved when printing.
I'll let you know the results.
Best regards
David.P
Re: Urgent -- despeckle PDF without/before OCR
Posted: Tue May 13, 2014 3:36 pm
by Tracker Supp-Stefan
Looking forward to it David!
Cheers,
Stefan
Re: Urgent -- despeckle PDF without/before OCR
Posted: Wed May 14, 2014 2:09 pm
by David.P
Stefan! That worked a treat!
Thank you for your idea!
PDF document before, not OCR'able:
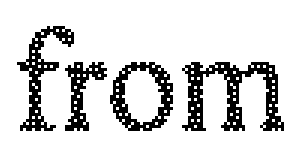
After printing to PDF with PDF-XChange with the settings below
(downsample from 300dpi b/w to 200dpi grey in order to get blurring):
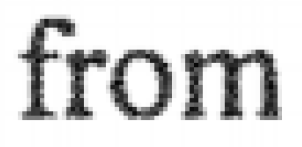
Then finally, after OCR:

And here's the printing settings:

Thanks once more!
Regards David.P
Re: Urgent -- despeckle PDF without/before OCR
Posted: Wed May 14, 2014 2:27 pm
by Tracker Supp-Stefan
Thanks for sharing this David!
And glad I could help.
Cheers,
Stefan
Re: Urgent -- despeckle PDF without/before OCR
Posted: Wed May 14, 2014 2:55 pm
by David.P
PS:
Here's an example for the amount of text that was (not) available before the procedure:

(only like 5 word fragments on two entire pages)
...and afterwards:

This saved my day (and possibly, my liability insurance:)
Regards David.P

Re: Urgent -- despeckle PDF without/before OCR
Posted: Wed May 14, 2014 3:14 pm
by Tracker Supp-Stefan
Re: Urgent -- despeckle PDF before OCR
Posted: Thu May 07, 2020 9:55 am
by David.P
Hi all,
Below is the successful Despeckle result again that I had got with the "Downsampling while Printing to PDF" method that Stefan had suggested:
David.P wrote: ↑Wed May 14, 2014 2:09 pm
PDF document before, not OCR'able:
After printing to PDF with PDF-XChange
(downsample from 300dpi b/w to 200dpi grey in order to get blurring):
Then finally, after OCR:
Now I just realized that there is the function "
Enhance Scanned Pages" in PDF-XChange Editor, which should do something similar, but possibly even better, and easier.
However, in my case this function, particularly the "Descreen" option, doesn't seem to do anything to the problematic pixelated text (that is almost impossible to OCR).
After applying "Descreening" this way, the text remains exactly the same as it was before, still containing the white dots:

Am I doing it wrong? If not, I would suggest to improve the Enhance Scanned Pages feature in order to be able to handle such problematic text that often is produced by scanners and fax machines.
One possibility to do so would be to apply a
Median filter to the image, which can produce results like the ones discussed further above:
David.P wrote: ↑Tue May 13, 2014 10:58 am
I have some large pdf files here that have been generated elsewhere by scanning paper documents. Unfortunately, the text looks like this:
With all of the OCR tools that I own, such text is not recognisable.
However,
after running a Median Filter (aka "despeckle") over the image (using IrfanView), the image looks like this:
... and is perfectly converted to text for example by Ad*be Acr*bat ClearScan:
Now the problem is, how can I batch-despeckle those PDF documents of several hundred pages size, such that I can OCR them afterwards with the tool of my choice?
I am attaching the example document that I have used in the above.
Thanks very much for considering adding a Median-like filter engine to the Enhance Scanned Pages function of PDF-XChange Editor!
Best regards
David
--
PS: I believe that this thread could be moved to the PDF-XChange Editor Forum because it actually deals with features of PDF-XChange Editor.
Re: Despeckle PDF before OCR
Posted: Thu May 07, 2020 9:10 pm
by TrackerSupp-Daniel
Hi, David.P
The descreen option is intended to do the opposite here, by removing halftone, IE: if you tried running it on the "printed" version of the file the software would attempt to make it look more like the original.
We have since implemented a "rasterize pages" function, which should be able to accomplish what you are looking for without the print operation being necessary (and as a bonus it is found on the Convert tab, near the OCR button, so no more "tab hopping" to find the right button!)
Kind regards,
Re: Despeckle PDF before OCR
Posted: Mon May 11, 2020 8:11 am
by David.P
Hello Daniel,
thank you for the explanation of what the "descreen" option does, and also for the idea to use the "rasterize pages" function for blurring problematic text before OCR.
I will make sure to try this approach.
Best regards
David
Despeckle PDF before OCR
Posted: Tue May 12, 2020 6:34 am
by Sasha - Tracker Dev Team